Recently, diffusion models (DMs) have been increasingly used in audio processing tasks, including speech super-resolution (SR), which aims to restore high-frequency content given low-resolution speech utterances. This is commonly achieved by conditioning the network of noise predictor with low-resolution audio. In this paper, we propose a novel sampling algorithm that communicates the information of the low-resolution audio via the reverse sampling process of DMs. The proposed method can be a drop-in replacement for the vanilla sampling process and can significantly improve the performance of the existing works. Moreover, by coupling the proposed sampling method with an unconditional DM, i.e., a DM with no auxiliary inputs to its noise predictor, we can generalize it to a wide range of SR setups. We also attain state-of-the-art results on the VCTK Multi-Speaker benchmark with this novel formulation.
Animation of the Bandwidth Extension Process (200 steps, 12k to 48k)
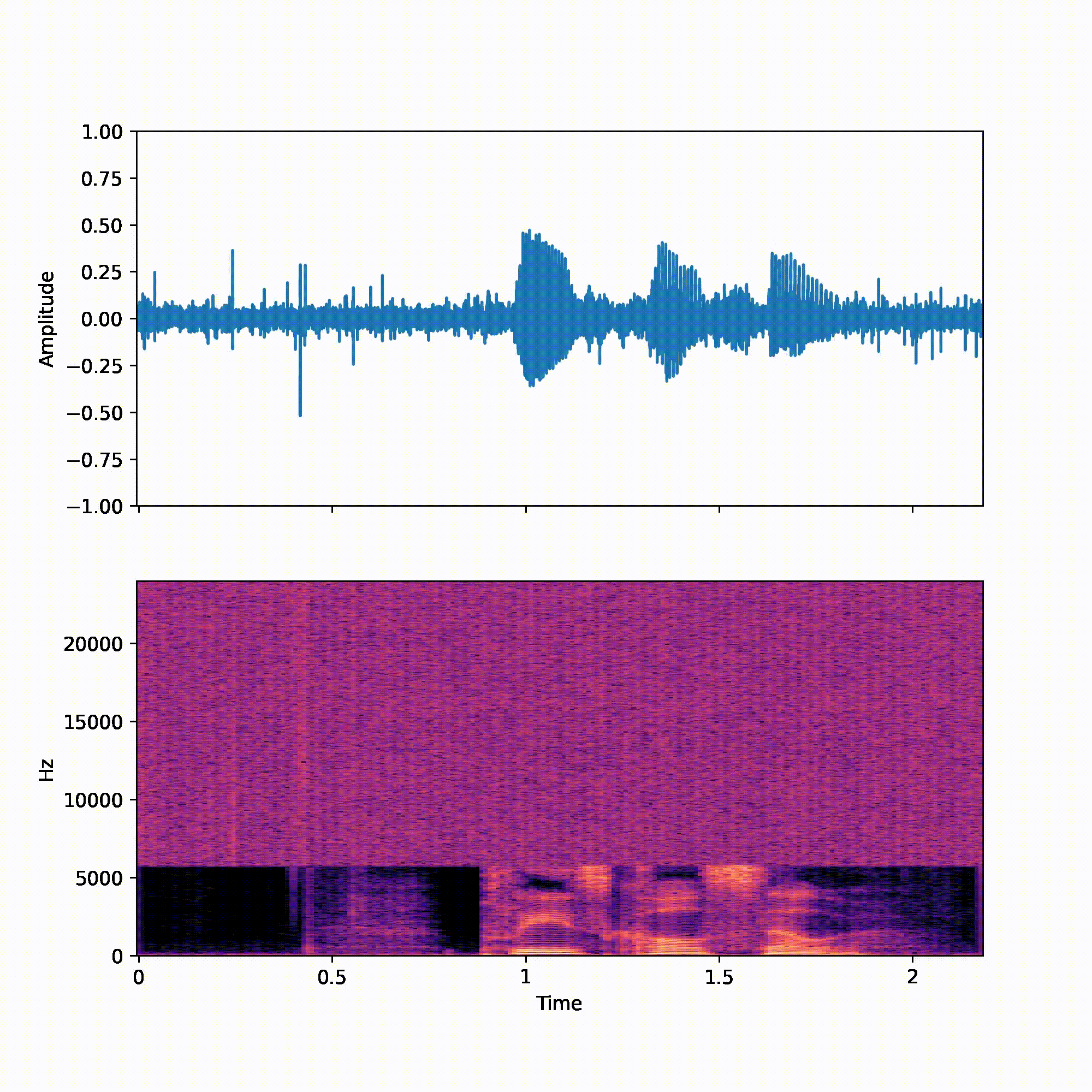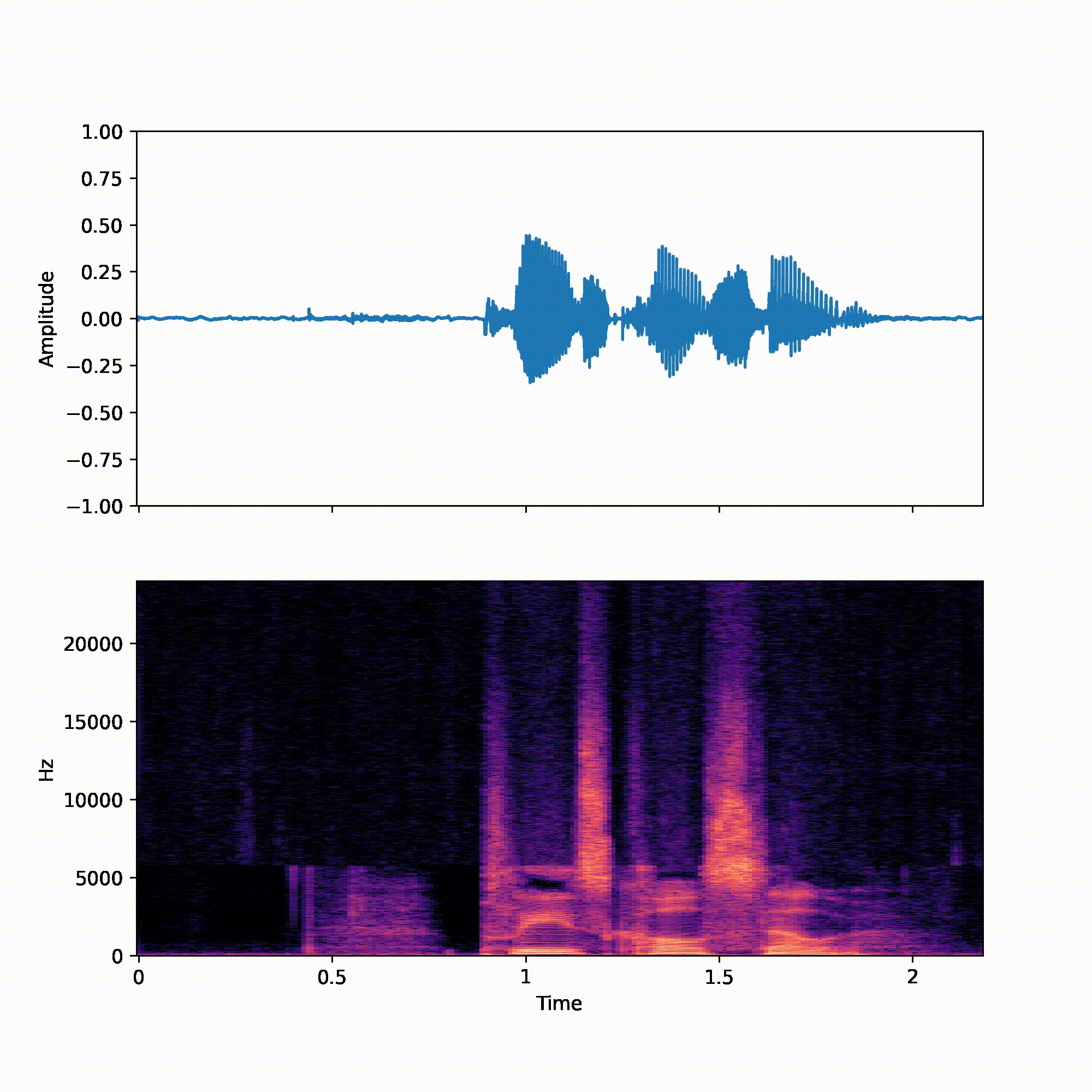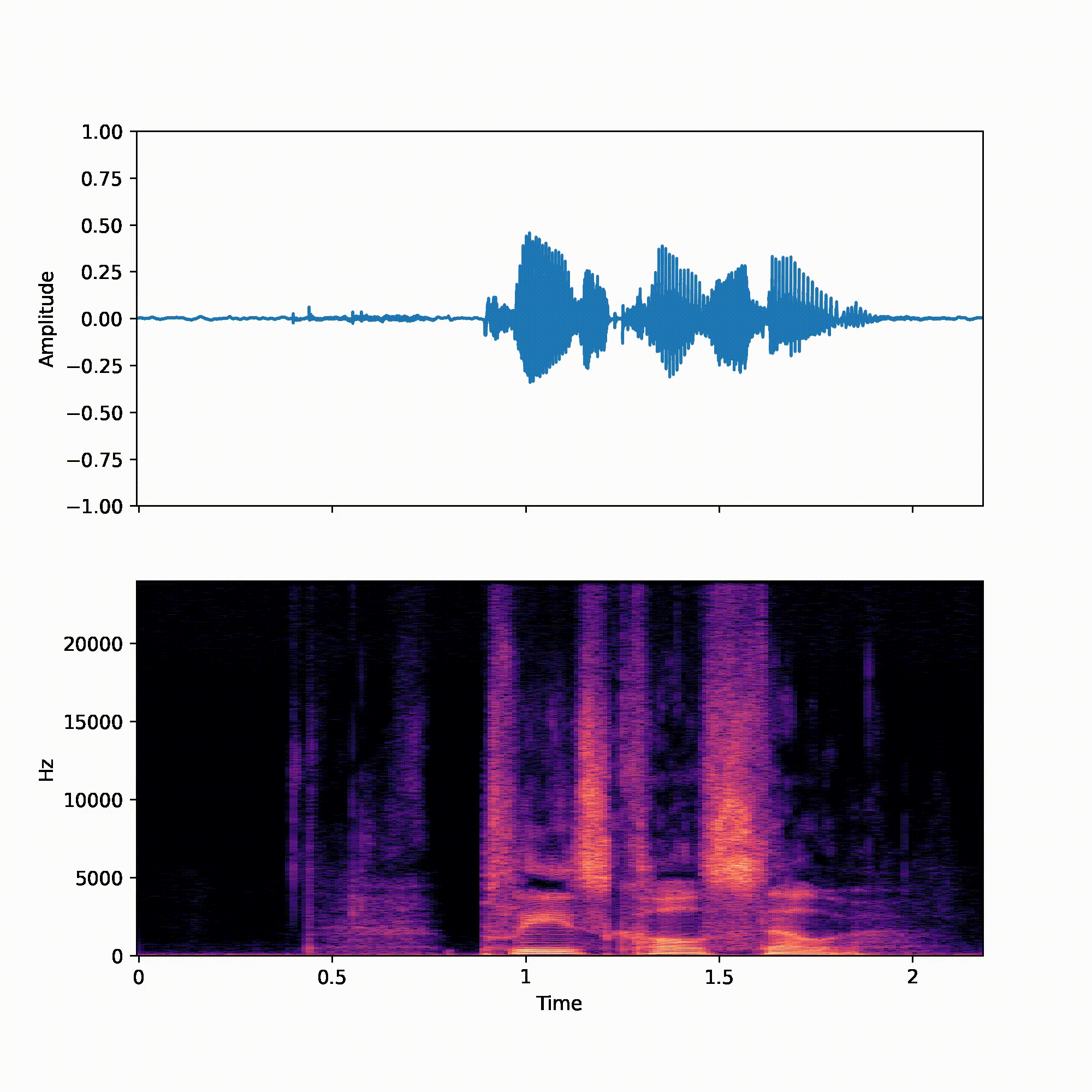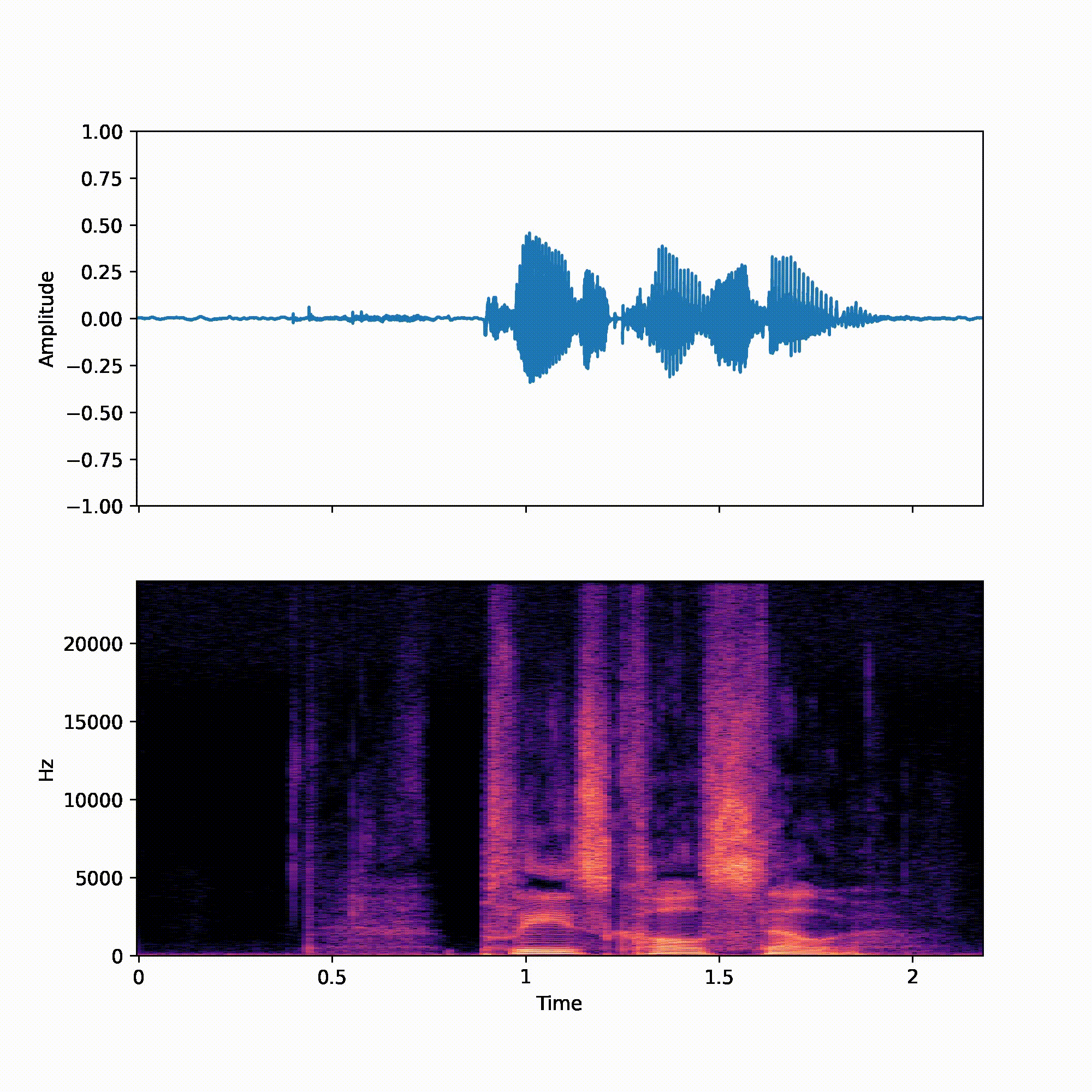
We recommend reader listen to the samples when reading the paper. All utterances were randomly picked from the VCTK test set.
Samples: 24k to 48k, 50 steps
We recommend using headphones for this section.
| p360_001 | p361_002 | |
|---|---|---|
 |
 |
|
| Input | ||
 |
 |
|
| Target | ||
 |
 |
|
| NU-Wave | ||
 |
 |
|
| NU-Wave+ | ||
 |
 |
|
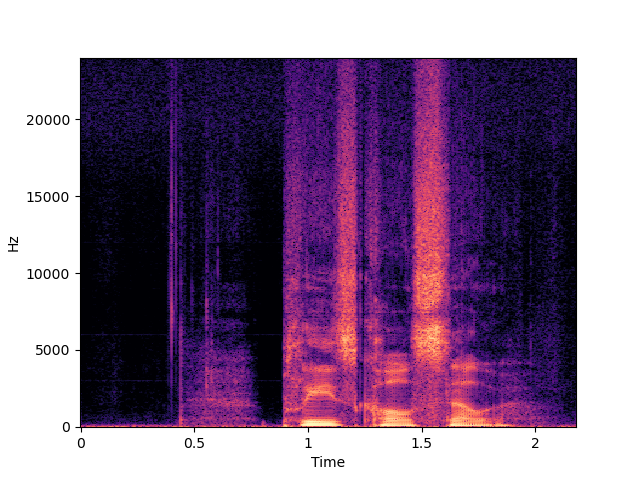
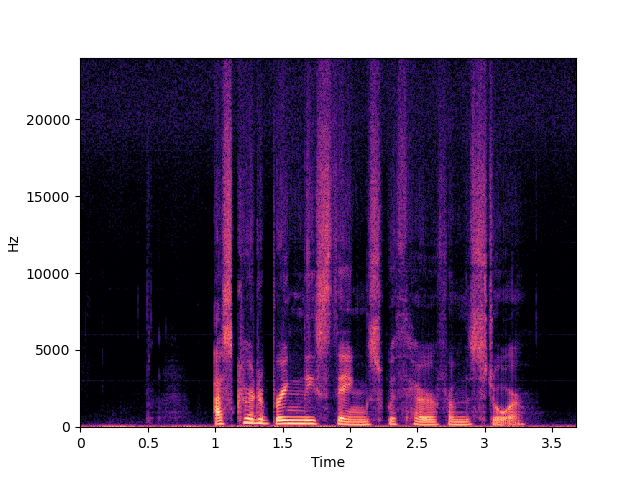
| NU-Wave 2 | ||
 |
 |
|
| NU-Wave 2+ | ||
 |
 |
|
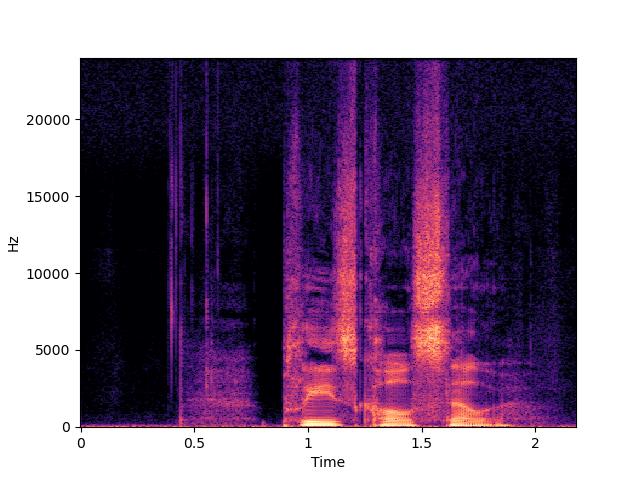
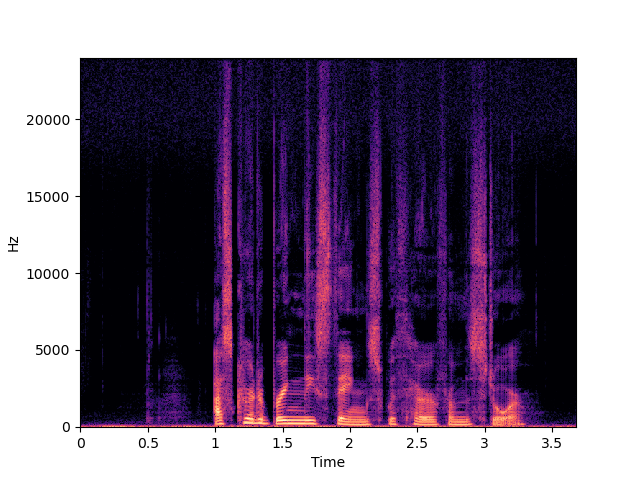
| WSRGlow | ||
 |
 |
|
| UDM+ |
Samples: 16k to 48k, 50 steps
We recommend using headphones for this section.
| p363_004 | p364_005 | |
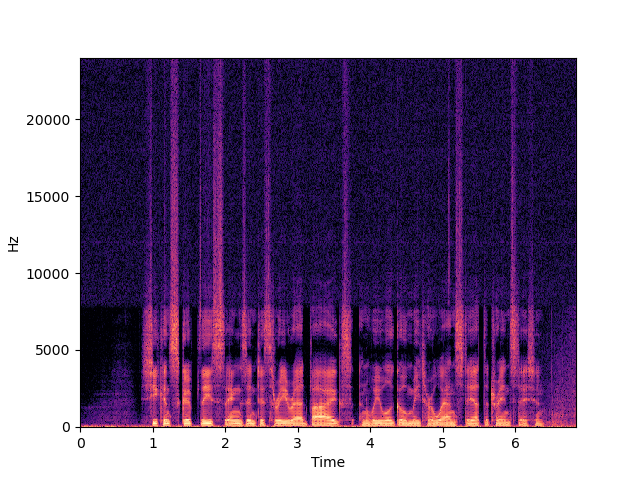
|---|---|---|
 |
 |
|
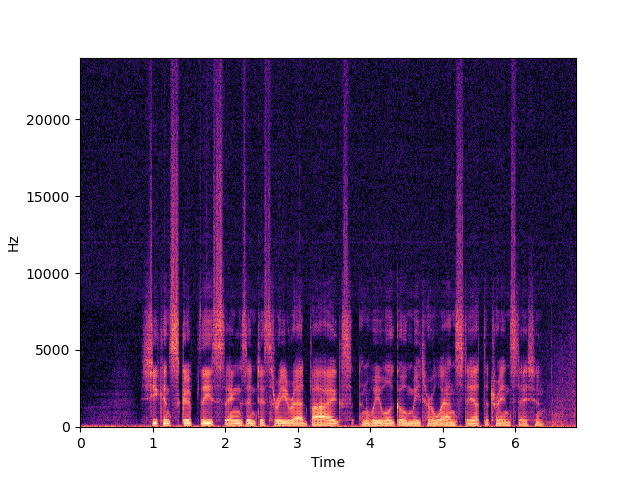
| Input | ||
 |
 |
|
| Target | ||
 |
 |
|
| NU-Wave | ||
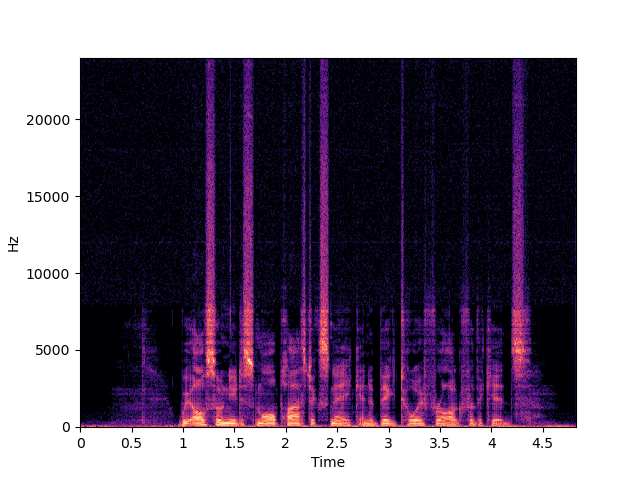 |
 |
|
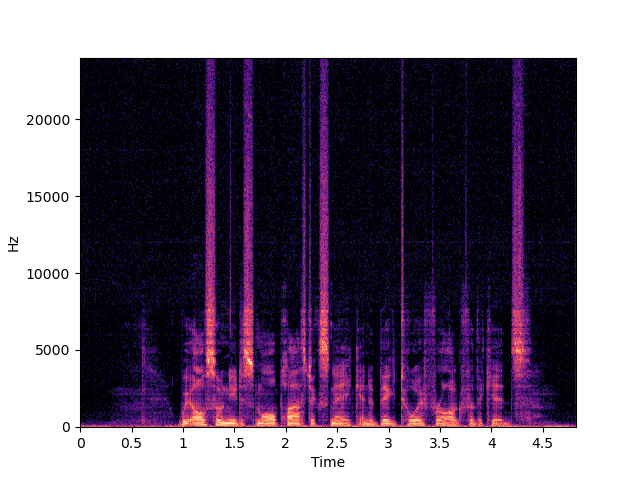
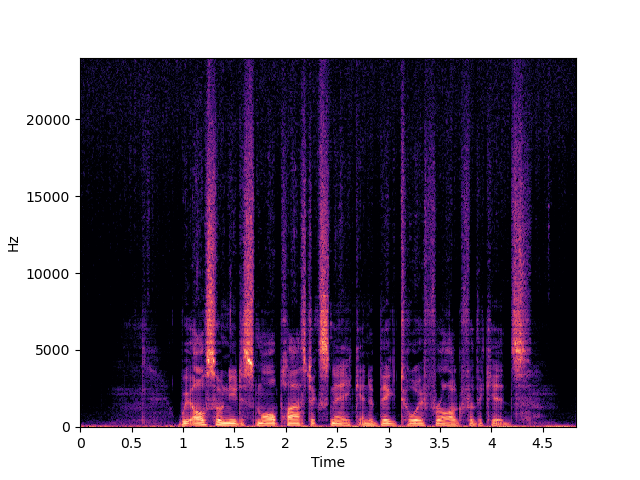
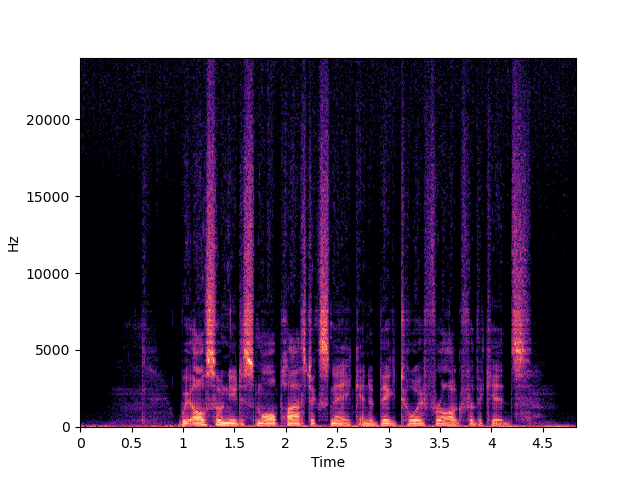
| NU-Wave+ | ||
 |
 |
|
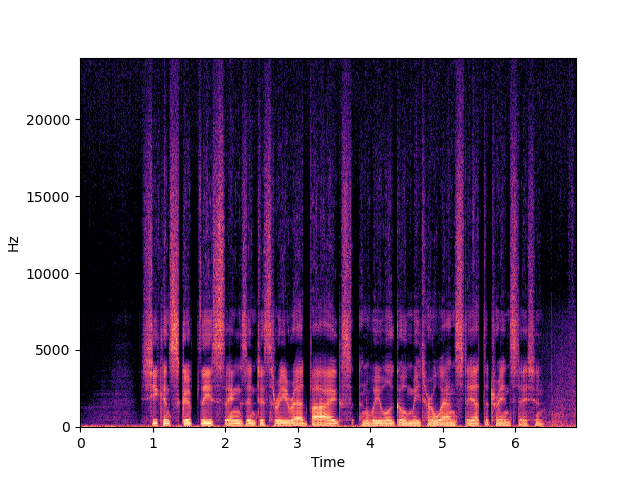
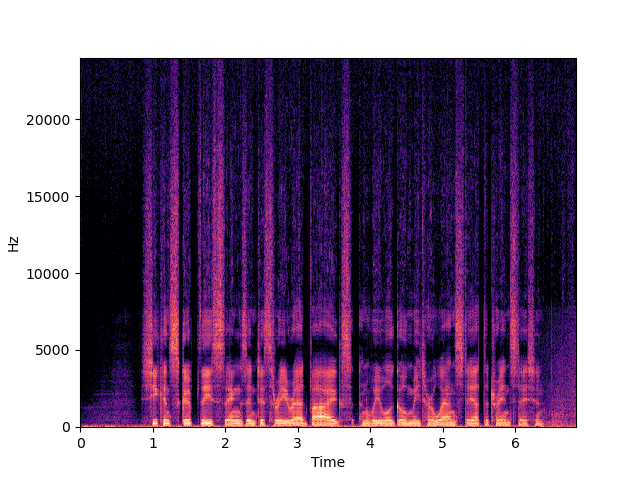
| NU-Wave 2 | ||
 |
 |
|
| NU-Wave 2+ | ||
 |
 |
|
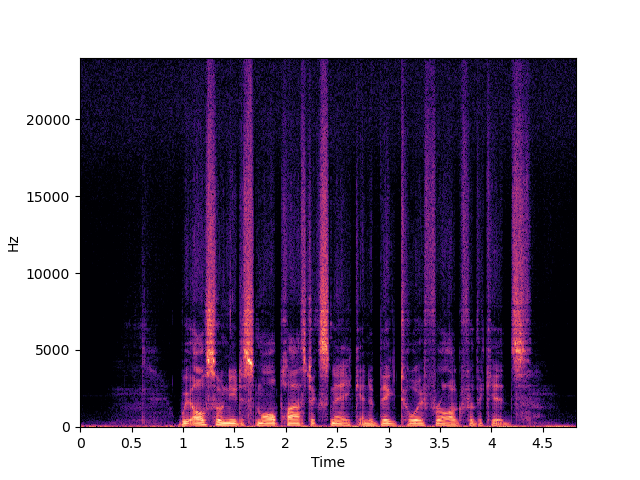
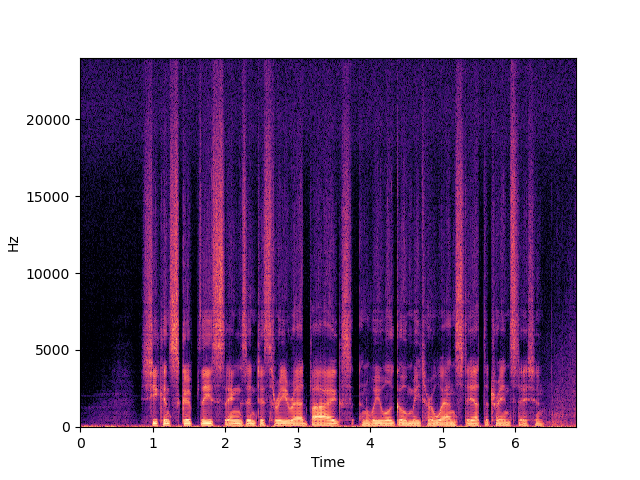
| WSRGlow | ||
 |
 |
|
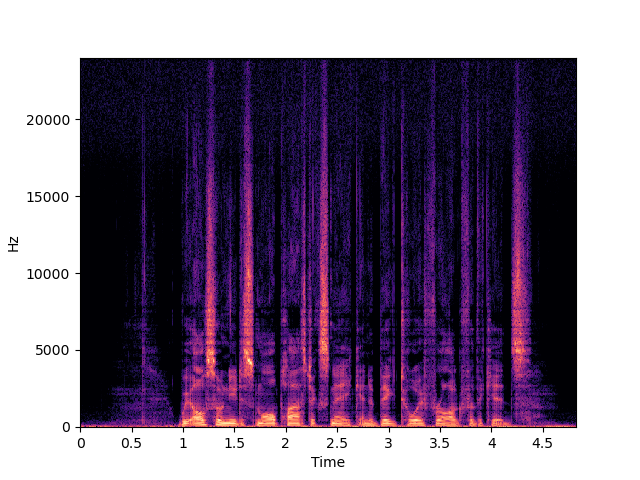
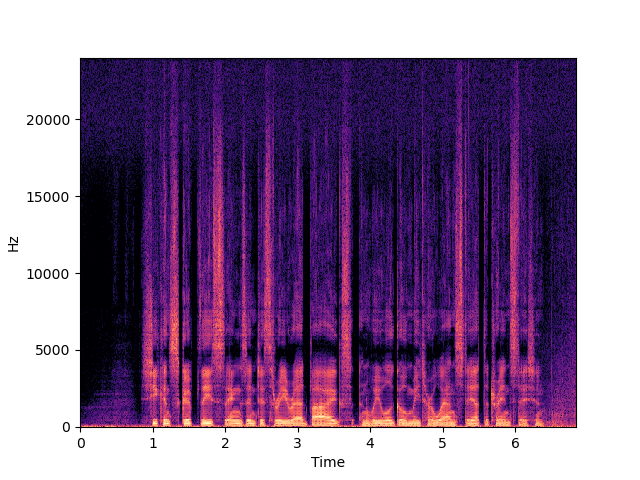
| UDM+ |
Samples: 8k to 16k, 50 steps
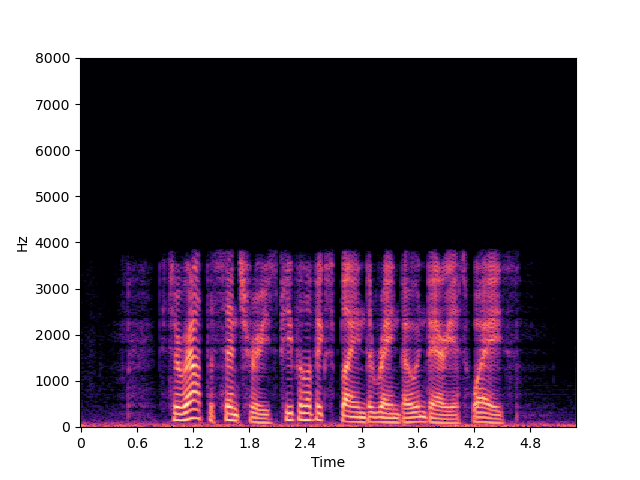
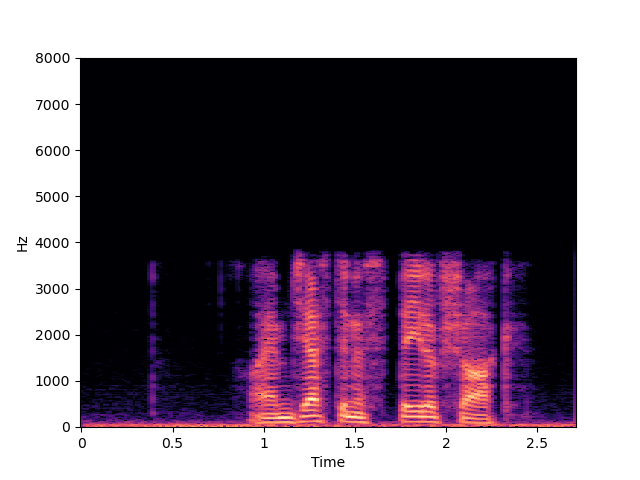
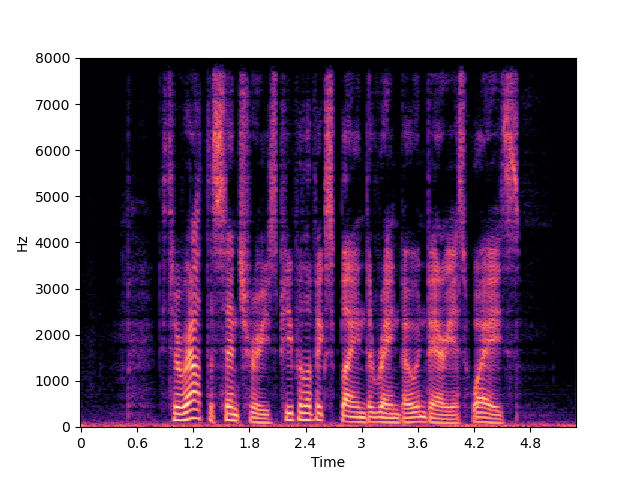
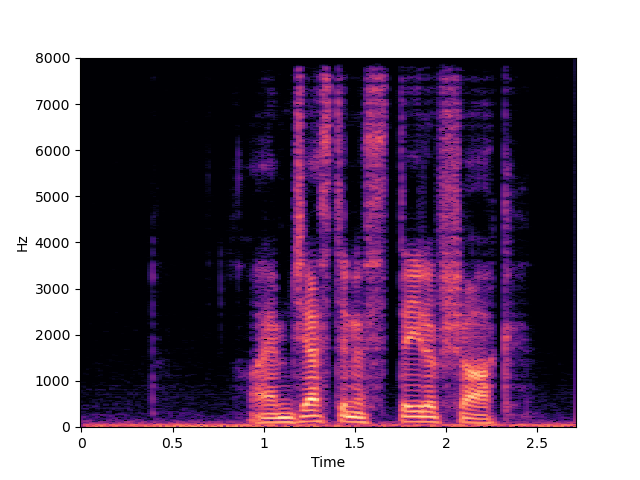
| p374_012 | p376_233 | |
|---|---|---|
 |
 |
|
| Input | ||
 |
 |
|
| Target | ||
 |
 |
|
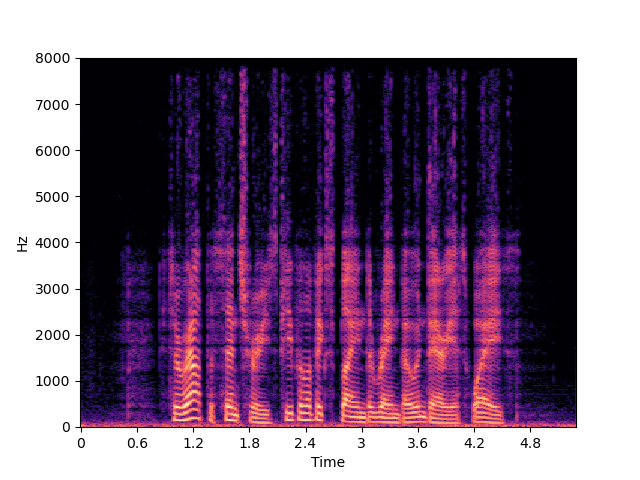
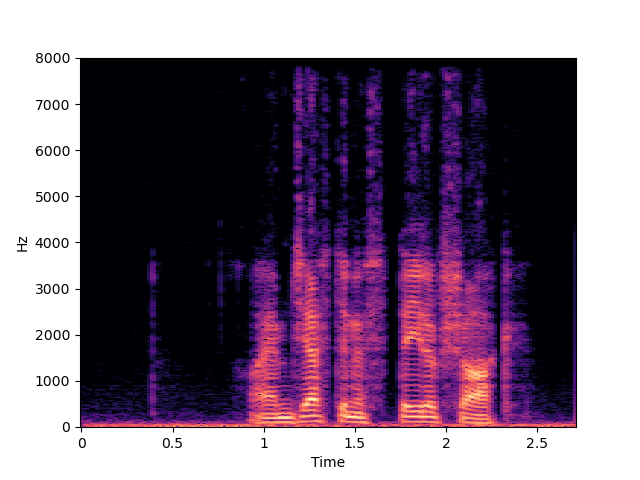
| NU-Wave 2 | ||
 |
 |
|
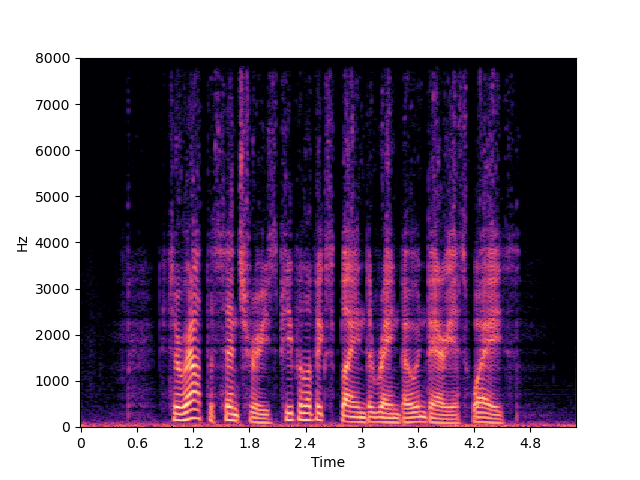
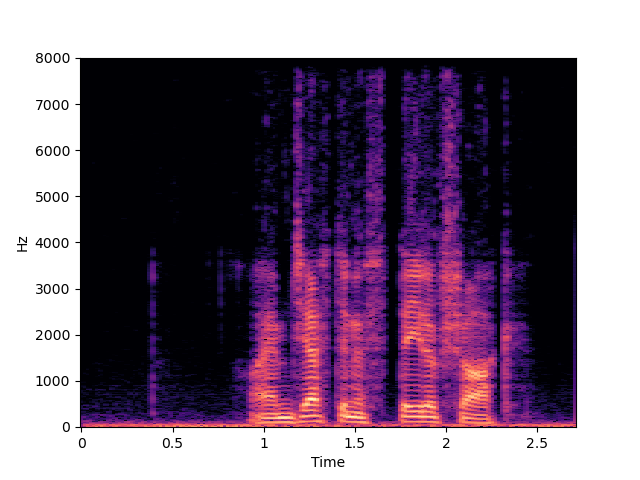
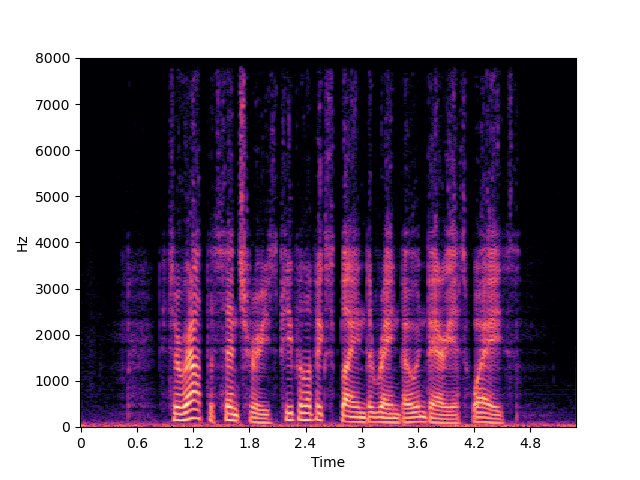
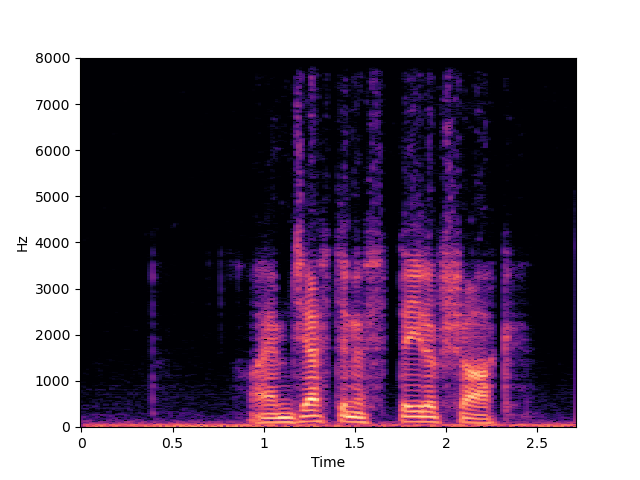
| NU-Wave 2+ | ||
 |
 |
|
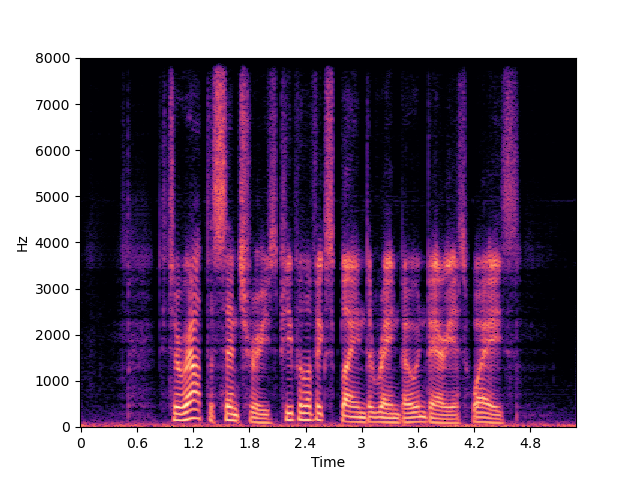
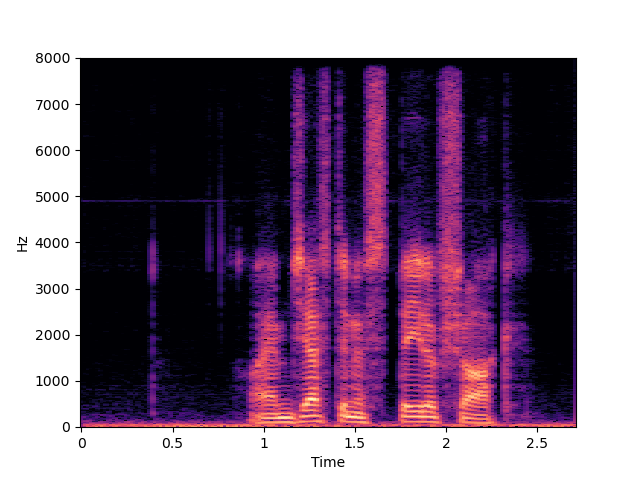
| NU-Wave 2+ w/o MCG | ||
 |
 |
|
| NVSR | ||
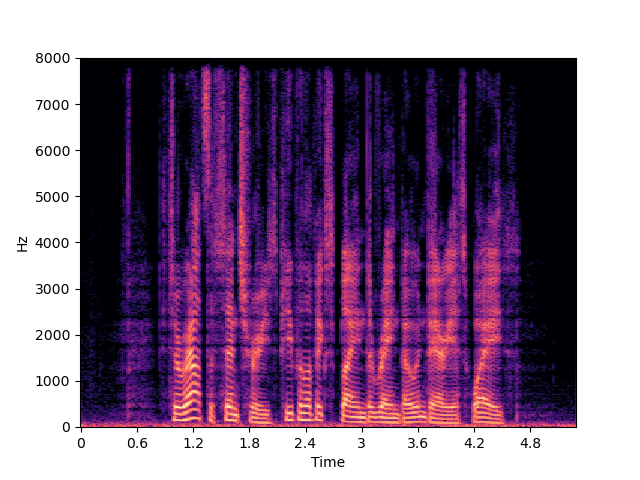 |
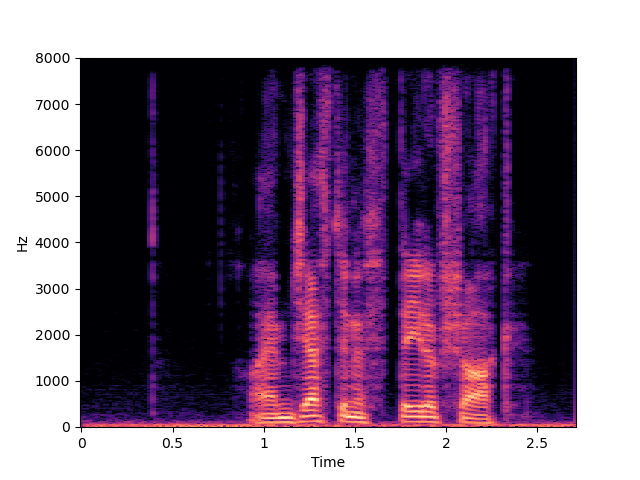 |
|
| UDM+ | ||
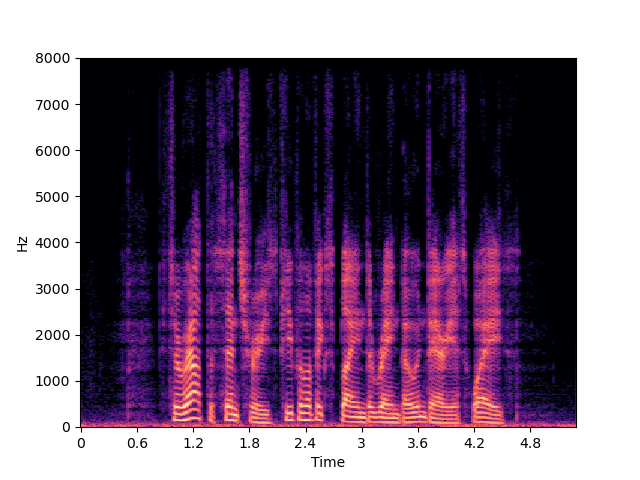 |
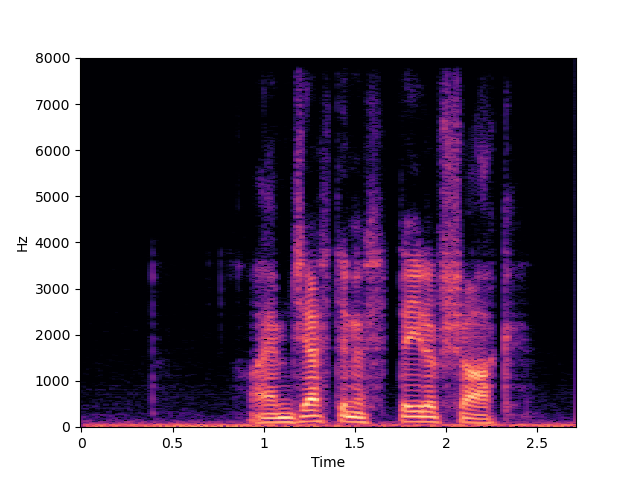 |
|
| UDM+ w/o MCG |
Unconditional Samples
In this section, the samples were generated unconditionally, using our noise predictor with 100 steps.